
알고리즘 문제를 풀다 보면 Scanner를 사용하다가 시간 초과를 겪는 경우가 있습니다.

테스트케이스에서는 통과했는데 제출하니 시간 초과 ???
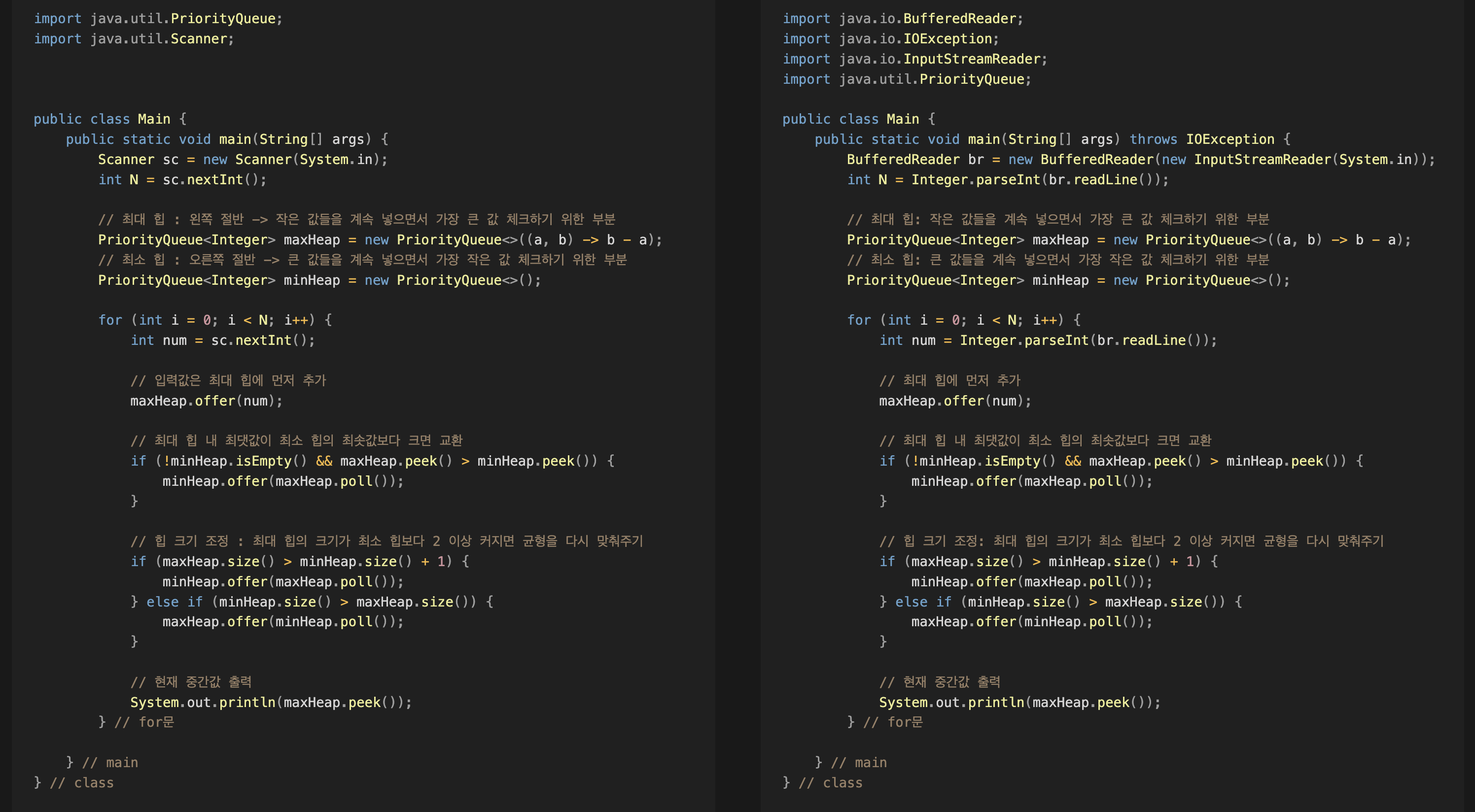
이처럼 입력부만 Scanner -> BufferedReader로 바꾸니 바로 통과되는 경우가 많았는데요 !
Scanner는 배우기 쉽고 편하지만, 이처럼 시간초과라는 문제를 초래하기도 합니다.
그렇다면, 왜 Scanner 대신 BufferedReader를 사용해야 하고,
어떻게 사용하는지에 대해 한번 알아보도록 하겠습니다.
1. Scanner vs BufferedReader 비교
| 구분 | Scanner | BufferedReader |
| 속도 | 상대적으로 느림 (정규식 기반 파싱) | 빠름 (버퍼 단위 입력) |
| 입력 단위 | 공백(next()) / 줄(nextLine()) | 줄 단위(readLine()) |
| 파싱 | 자동 변환 지원 (정수, 실수 등) | 문자열만 반환 → 직접 파싱 필요 |
| 코드 난이도 | 간단 | 조금 복잡 |
| 적합한 경우 | 소규모 입력, 간단 실습 | 대규모 입력, 코딩테스트, 파일 입출력 |
쉬운 예시를 통해 살펴보겠습니다.
https://www.acmicpc.net/problem/10818

Scanner 동작 방식
1. 첫 줄 5 읽기 : nextInt() 호출
- 내부에서 정규식 검사(정수인지) -> 정수 변환
2. 두 번째 줄 "20 10 35 30 7" 읽기 : nextInt() 5번 호출
- 호출할 때마다 정규식 검사 -> 정수 변환
즉, 숫자 하나 읽을 때마다 정규식을 돌려서 시간과 메모리 낭비가 발생합니다.
BufferedReader 동작 방식
1. 첫 줄 5 읽기 : Integer.parseInt("5")
2. 두 번째 줄 "20 10 35 30 7" 통째로 읽기
3. StringTokenizer로 20, 10, 35, 30, 7 분리
4. 정수로 변환 후 배열 저장
즉, 한 줄을 통째로 읽어 처리하므로 시간과 메모리 낭비를 줄일 수 있습니다.
2. BufferedReader 원리
- 데이터를 8KB(8192 byte) 버퍼에 먼저 모아둡니다.
- 프로그램에서 readLinke()을 호출하면, 이미 버퍼에 쌓여있는 데이터를 줄 단위로 꺼냅니다. (정규식 검사 XX)
- 정규식 검사가 없고, 문자열만 반환하기 때문에 원하는 타입으로 변환은 직접 수행해야 합니다. (Integer.parseInt 등)
- 대신, 대용량 입력일수록 훨씬 빠르게 처리할 수 있습니다.
버퍼(Buffer)의 개념
버퍼는 데이터를 임시로 저장하는 중간 창고입니다.
입출력 장치는 CPU보다 느리기 때문에, 버퍼에 데이터를 모았다가 한꺼번에 전달하면 호출 횟수가 줄어들어 속도가 빨라집니다.
3. BufferedReader 기본 사용법
import java.io.*;
import java.util.*;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
// 한 줄 입력
String line = br.readLine();
System.out.println(line);
// 공백 단위 입력
StringTokenizer st = new StringTokenizer(br.readLine());
int a = Integer.parseInt(st.nextToken());
int b = Integer.parseInt(st.nextToken());
System.out.println(a + b);
br.close();
}
}- readLine() : 한 줄 통째로 문자열 반환
- StringTokenizer : 문자열 공백 단위 분리
- Integer.parseInt() : 정수 변환
Tip. 입력이 여러 줄에 걸쳐 들어오는 경우이러한 패턴으로 토큰 고갈 대비를 해주면 안전합니다.while (!st.hasMoreTokens()) st = new StringTokenizer(br.readLine());
4. 출력 최적화: BufferedWriter
입력이 많을 때뿐 아니라 출력도 많다면 System.out.println 대신 BufferedWriter를 씁니다.
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
for (int i = 1; i <= 10; i++) {
bw.write(i + "\n");
}
bw.flush();
bw.close();
출력 내용을 버퍼에 모았다가 flush()로 한 번에 내보내기 때문에 대량 출력 시 효율적입니다.
5. 알고리즘에서 자주 쓰는 패턴
간단한 문제들을 통해 자주 쓰는 패턴에 대해 살펴보겠습니다 !
정수 1개 입력 https://www.acmicpc.net/problem/10818

int n = Integer.parseInt(br.readLine());
정수 여러 개 입력 https://www.acmicpc.net/problem/10871

StringTokenizer st = new StringTokenizer(br.readLine());
int a = Integer.parseInt(st.nextToken());
int b = Integer.parseInt(st.nextToken());
정수 배열 입력 https://www.acmicpc.net/problem/10807

int n = Integer.parseInt(br.readLine());
int[] arr = new int[n];
StringTokenizer st = new StringTokenizer(br.readLine());
for (int i = 0; i < n; i++) arr[i] = Integer.parseInt(st.nextToken());
2차원 배열 입력 https://www.acmicpc.net/problem/10810

StringTokenizer st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken());
int m = Integer.parseInt(st.nextToken());
int[][] arr = new int[n][m];
for (int i = 0; i < n; i++) {
st = new StringTokenizer(br.readLine());
for (int j = 0; j < m; j++) {
arr[i][j] = Integer.parseInt(st.nextToken());
}
}
대량 출력 https://www.acmicpc.net/problem/15552
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
for (int i = 1; i <= 100; i++) bw.write(i + "\n");
bw.flush();
bw.close();
6. Scanner → BufferedReader 변환 예시

마무리
- Scanner : 쉽고 간편하지만 대량 입력에서는 정규식 비용으로 느려짐
- BufferedReader: 직접 파싱이 필요하지만 훨씬 빠르며 코테 표준
- BufferedWriter: 출력이 많을수록 효과가 큼
따라서 알고리즘 문제에서는 BufferedReader + StringTokenizer + BufferedWriter 조합을 기본 템플릿으로 삼는 것이 가장 효율적입니다.
이제는 BufferedReader를 습관화해 시간 초과 걱정 없이 더 빠르게 문제를 풀어보세요 !
'알고리즘' 카테고리의 다른 글
| 알고리즘을 공부하면서 깨달은 점.zip (1) | 2025.11.24 |
|---|---|
| [TIL] 알고리즘 BFS & DFS 정리 (0) | 2025.09.23 |
| 알고리즘 공부 정리 (3) | 2025.08.29 |
| 조합과 순열 : 개념부터 구현 방식까지 정리 (0) | 2025.05.05 |
| 자바 문자열 핵심 정리 (0) | 2025.03.22 |